


Om met de deur in huis te vallen: alle resultaten uit de 1e ronde zijn door deelnemers beoordeeld en gewaardeerd in de unieke 2e ronde. De mens heeft het belangrijkste werk gedaan: betekenis geven aan elkaars bijdragen. Dat kunnen algoritmes gewoonweg niet. De deelnemers hebben de bijdragen aan de 1e ronde dus van context voorzien, op waarde geschat: via de scores tussen -3 en +3. Bovendien hebben ze woorden aangeklikt die belangrijk zijn voor deze scores en zelfs de scores toegelicht. Ook over de bijdragen die ze als groep het allerminst steunen of zelfs afwijzen. Dat is een unieke rijkdom aan inzichten en laat daarmee de enquête – die geen 2e ronde kent – voorgoed achter zich. Je dialoog is maximaal actiegericht: kaf van het koren wordt gescheiden en verrijkt met aanbevelingen. Bovendien voelen deelnemers zich daardoor enorm serieus genomen, betrokken en bouw je draagvlak bij ze op. Dat is zeker onze felicitatie waard! Wat is de slimste, snelste, beste manier om door de resultaten heen te gaan en tot actie over te gaan? De meeste gebruikers van CircleLytics Dialogue ondernemen binnen één of enkele dagen actie, sommigen zelfs op de dag zelf!
Als je de dialoog hebt opgesteld met het eind van de dialoog in zicht, en ijzersterke vragen hebt ontworpen, is je werk nu nog eenvoudiger. Hoe beter je de dialoog hebt opgesteld, hoe hoger de respons, en hoe beter de deelnemers in ronde 2 met bijdragen van anderen aan de slag kunnen en deze kunnen waarderen. Onze algoritmes zorgen ervoor dat die 2e ronde super-aantrekkelijk is en dat blijkt uit de data zo te zijn: meer dan 70% van de deelnemers wordt zo nieuwsgierig gemaakt, wil zo graag leren van wat anderen zeggen, dat ze meer dan hun 10-15 stuks bijdragen willen zien en waarderen! Na het eerste setje wat het algoritme hen toont in de 2e ronde, klikken ze meerdere keren om telkens weer 5 andere bijdragen te kunnen zien en op reflecteren. Ze stoppen dus enorm veel werk in jouw vraagstuk en dat zien we terug in de rijkdom van de data. Zij zetten de bijdragen uit de 1e ronde om in gestructureerde, geprioriteerde overzichten.
Onderstaand is onze volgorde, onze aanbeveling, om door de resultaten heen te lopen en snel tot actie over te gaan. Vergeet daarbij niet: als je deelnemers in de 2e ronde hebt gevraagd om de bijdragen die zij het belangrijkst vinden, te voorzien van hun aanbeveling om deze snel en succesvol uit te voeren, je nóg sneller weet wat je te doen staat. Om bij de basis te beginnen:
- alle data is gedurende en na je dialoog realtime beschikbaar: je bent dus zelfstandig en onafhankelijk
- alle data is te downloaden in excel of pdf, of als plaatje (grafieken/tabellen)
- onze tools helpen jou om zelf extra analyses uit te voeren
- jij staat centraal en jij bent de baas over jouw data.
Je eerste stap en snelste resultaat: Top en Bottom 5 (15 min tijd)
Je kunt per vraag de hoogst scorende en de laagst scorende 5 bijdragen uitlezen. Dit is dus bepaald door de groep in de 2e ronde. Je hoeft dus zelf niets te turven noch te vertrouwen op topic modelling of iets dergelijks: de mensen zelf weten het beste wat ze bij nader inzien willen en belangrijk vinden of juist afwijzen. Daar kan geen grafiek of word cloud tegenop natuurlijk. De top 5 en bottom 5 zijn concreet en via tabjes beschikbaar per vraag. Je kunt hier de thema’s uithalen die er het meest toe doen. 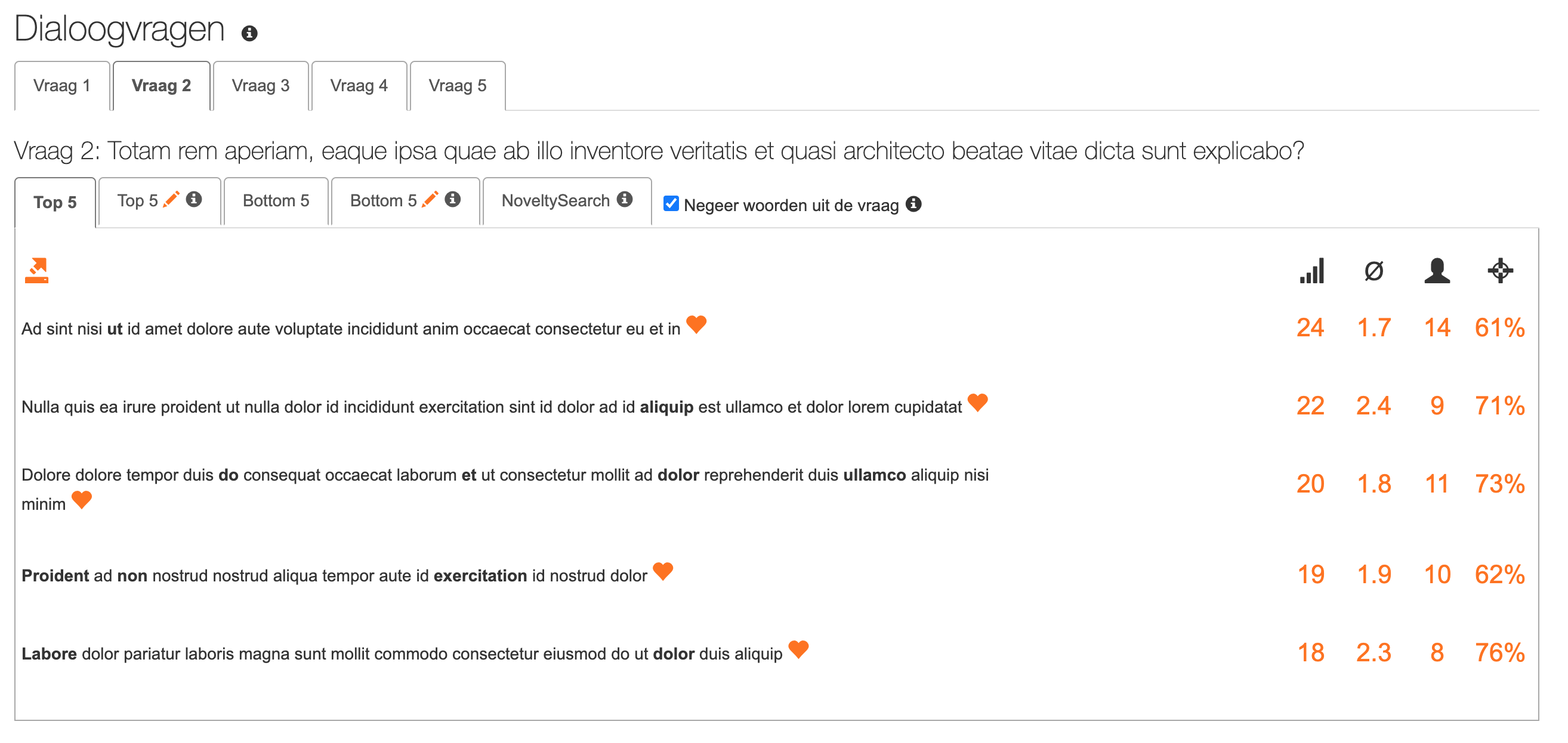 Deze noteer je op het digitale notitieblokje dat je bovenin aantreft of zet deze meteen in bijvoorbeeld je presentatie/document voor anderen. De letterlijke bijdragen zelf geven kleur en nuance aan het thema, dus deze kun je (selectief) eveneens in je presentatie of andere rapportage opnemen. Handig om niet alleen naar de top 5 of bottom 5 te kijken maar naar de bovenste 10% of 10 bijdragen en onderste 10% of 10 bijdragen.
Deze noteer je op het digitale notitieblokje dat je bovenin aantreft of zet deze meteen in bijvoorbeeld je presentatie/document voor anderen. De letterlijke bijdragen zelf geven kleur en nuance aan het thema, dus deze kun je (selectief) eveneens in je presentatie of andere rapportage opnemen. Handig om niet alleen naar de top 5 of bottom 5 te kijken maar naar de bovenste 10% of 10 bijdragen en onderste 10% of 10 bijdragen.
Nieuwsgierig naar wat CircleLytics voor jou betekent? Plan hier je demo of kennismaking.
Aangepaste Top 5 / Bottom 5 (nog eens 15 min)
Je kunt de tabjes gebruiken waar het potloodje op staat, dus Top 5 en Bottom 5 met het potloodje. Daar kun je één of meer bijdragen verbergen (dus niet verwijderen) en daardoor dus een aangepaste top maken. Je schoont de top als het ware op. Dit doe je net zolang tot je een goed onderscheidende top hebt, of tot de bijdragen niet meer voldoende hoge totaal scores hebben (en immers dan dus geen draagvlak meer hebben). Elke keer als je een bijdrage verbergt, schuift de tool de volgende in de rij erin. Zo kun je snel ontdubbelen – en heb je dat in eigen hand. Als je terugkoppelt aan jouw achterban, dan kun je bijvoorbeeld laten zien dat je je analyse startte met de Top 5, je deze hebt opgeschoond tot een aangepaste Top 5. Stel dat je 10 meningen hebt verborgen, dan heb je dus naar de bovenste 10 gekeken en daarbij meningen hebt verborgen als ze al voorkomen in de Top 5.
Het waarom achter de scores van top-resultaten: het hartje
Achter de bijdragen zie je telkens een hartje. Dat hartje kun je klikken en bevat de onderbouwingen die deelnemers hebben gegeven bij hun scores in de 2e ronde voor die bijdrage. Hierdoor kom je erachter wat hun ‘waarom’ is achter de score die ze gaven. Niet bij elke score die ze gaven hebben ze een onderbouwing achtergelaten maar wel zeer vaak. Je kunt deze onderbouwingen van de Top 5 bijvoorbeeld doornemen om het waarom achter de (hoogste) scores te begrijpen. Nu je het waarom kent, kun je voorkomen dat je naderhand discussie over de resultaten hebt en moet gissen naar waarom iets omhoog of omlaag is gescoord door de groep. Dat is de kracht van het open antwoord en de bundeling ervan in CircleLytics Dialogue. Dat scheelt behalve gedoe, ook vooral tijd en je voorkomt dat het op de stapel komt te liggen: sneller tot actie komen dus. Zo worden managers en leidinggevenden snel geholpen en hoeven ze niet te staren naar grafieken, trendlijnen en andere cijfermatige overzichten. Anders gezegd: nu je zo concreet weet waar wel en geen draagvlak voor bestaat en waarom deelnemers dat zeggen, is het slimmer om zo snel mogelijk te laten zien dat je het in daden omzet.
Speld in de hooiberg: NoveltySearch
Een ander tabje op je Resultaten tab van je dialoog is NoveltySearch. We hebben alle bijdragen doorberekend op variantie, zeg maar de spreiding van de scores, op basis van de scores -3 en -2 en +3 en +2 die aan de betreffende bijdrage gegeven zijn in ronde 2. De uitschieters dus. Die variantie hebben we vermenigvuldigd met het aantal deelnemers bij die bijdrage. Dat levert een score op, die iets indiceert over de mate waarin deelnemers het niet zo eens waren met elkaar bij die bijdrage. Bekijk de top 5 hiervan, of download de volledige lijst, om te zien of er iets bijzit waar je rekening mee moet houden bij je besluitvorming of bij de uitvoering. Of je kunt overwegen een vervolgdialoog te voeren om het nader uitgesproken en uitgewerkt te krijgen. NoveltySearch graaft in alles tussen de Top en Bottom 5 en laat bijdragen zien die misschien iets blootleggen dat je niet wil mislopen. Beter ten halve gekeerd, dan ten hele gedwaald!
SupportIndicator SI%
Onze AI en de data van de 2e ronde samen geven aan in welke mate alle andere bijdragen lijken op deze ene bijdrage waarvoor je dit getal checkt. Wij gebruiken daar algoritmes voor die zich aanpassen aan de relevantie van de vraag en antwoorden zelf en nog een aantal factoren. Een hoog percentage wil zeggen dat er veel overeenkomstigheid is. Je gebruikt het % als indicatie van de mate van steun van alle deelnemers als ze allen deze bijdrage zouden hebben beoordeeld: als ze immers vergelijkbare bijdragen positief waarderen, dan is het waarschijnlijk dat ze dat voor deze ook zouden doen. Je kunt op het % klikken en dan zelf de door ons algoritme gegenereerde lijst corrigeren en samen met de tool tot een aangescherpte lijst komen, en aangescherpte SI%. Je kunt daarbij bijdragen uit de lijst (via het potloodje) klikken en verbergen (en daarmee de cijfermatige uitkomst corrigeren) en/of je kunt de bijdrage zelf in het boxje linksboven aanpassen in meer of mindere mate. De tool rekent alles meteen voor je door. Je analyseert dus samen met CircleLytics op een snelle, transparante manier.
Zelf analyseren en zoeken: supervised topic modelling
Je kunt aan de hand van de gevonden thema’s zelf verder zoeken via de zoekopdracht-box bij “Resultaat van collectieve intelligentie”. Neem een eerste thema dat je uit de Top 5 of bovenste 10 of 10% van de bijdragen hebt gehaald. Gebruik de beschikbare operators (via het help i-tje kun je lezen hoe/welke). Gebruik synoniemen en andere beschrijvingen die je tegenkomt in bijdragen. Maak ook gebruik van de WWC, Weighted Word Count (zie hieronder) om nog minder zelf te hoeven nadenken en kostbare tijd te besparen. Zo maak je een completere zoekopdracht. De tool voert deze automatisch en direct uit. Je resultaten kun je beoordelen: hoeveel bijdragen voldoen aan je zoekopdracht, welk percentage van het totaal? Hoeveel draagvlak of afwijzing hebben deze bijdragen opgehaald in ronde 2 en dus hoeveel (gewogen totaal) aan positieve, respectievelijk negatieve waardering? En van hoeveel unieke, daarbij betrokken deelnemers? Als je zodanig hebt gezocht dat je resultaten veel draagvlak laten zien, heb je je analyse klaar tav dat thema. Je kunt deze opslaan en / of als excel downloaden. De 3 donut grafieken kun je samen met het thema opnemen in jouw eigen rapportage. Kijk maar eens naar dit onderstaande plaatje. 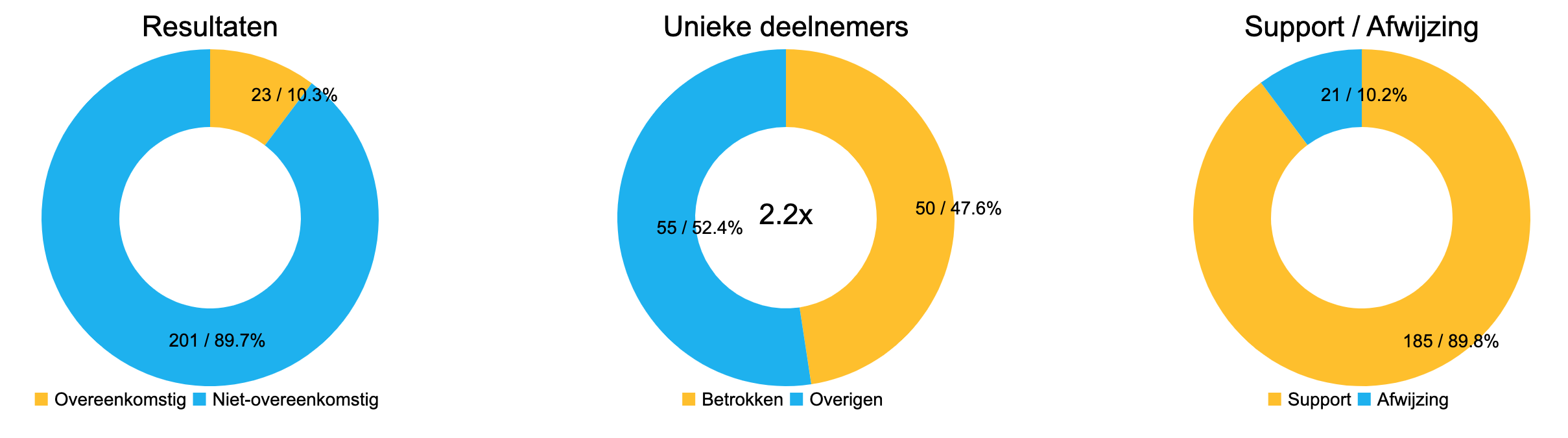 Zo snel gaat dat. De tool en jij doen samen het werk. Het vergt geen bijzondere vaardigheden weten we uit betrouwbare bron: onze klanten. Het is enorm overtuigend te zien dat een thema meestal laat zien dat wat in de 1e ronde is gezegd door deelnemers (bijvoorbeeld iets wat heel vaak werd gezegd) veel minder steun krijgt van de deelnemers ‘bij nader inzien’ …. Of andersom: iets wat niet vaak genoemd werd, krijgt ineens heel veel steun, van veel unieke deelnemers. Je zult dan verder overtuigd raken van de feiten: zonder 2e ronde kun je open antwoorden van mensen niet begrijpen: het is noodzakelijk aan deelnemers te vragen of ze waarde en betekenis toekennen aan de antwoorden van anderen. Niets is minder vreemd dan het voortschrijden van ieders inzicht.
Zo snel gaat dat. De tool en jij doen samen het werk. Het vergt geen bijzondere vaardigheden weten we uit betrouwbare bron: onze klanten. Het is enorm overtuigend te zien dat een thema meestal laat zien dat wat in de 1e ronde is gezegd door deelnemers (bijvoorbeeld iets wat heel vaak werd gezegd) veel minder steun krijgt van de deelnemers ‘bij nader inzien’ …. Of andersom: iets wat niet vaak genoemd werd, krijgt ineens heel veel steun, van veel unieke deelnemers. Je zult dan verder overtuigd raken van de feiten: zonder 2e ronde kun je open antwoorden van mensen niet begrijpen: het is noodzakelijk aan deelnemers te vragen of ze waarde en betekenis toekennen aan de antwoorden van anderen. Niets is minder vreemd dan het voortschrijden van ieders inzicht.
Weighted Word Count
Het is niet relevant of in de 1e ronde allerlei woorden of thema’s vaak worden genoemd. De gewone word count, de frequentie van voorkomen van woorden dus, is niet relevant, niet betekenisvol. Het gaat er immers om, of na de 2e ronde blijkt dat de deelnemers waarde toekennen aan wat anderen noemen. Die weging die ze aan bijdragen, woorden en daardoor aan thema’s geven is van belang en komt tot stand door de scores -3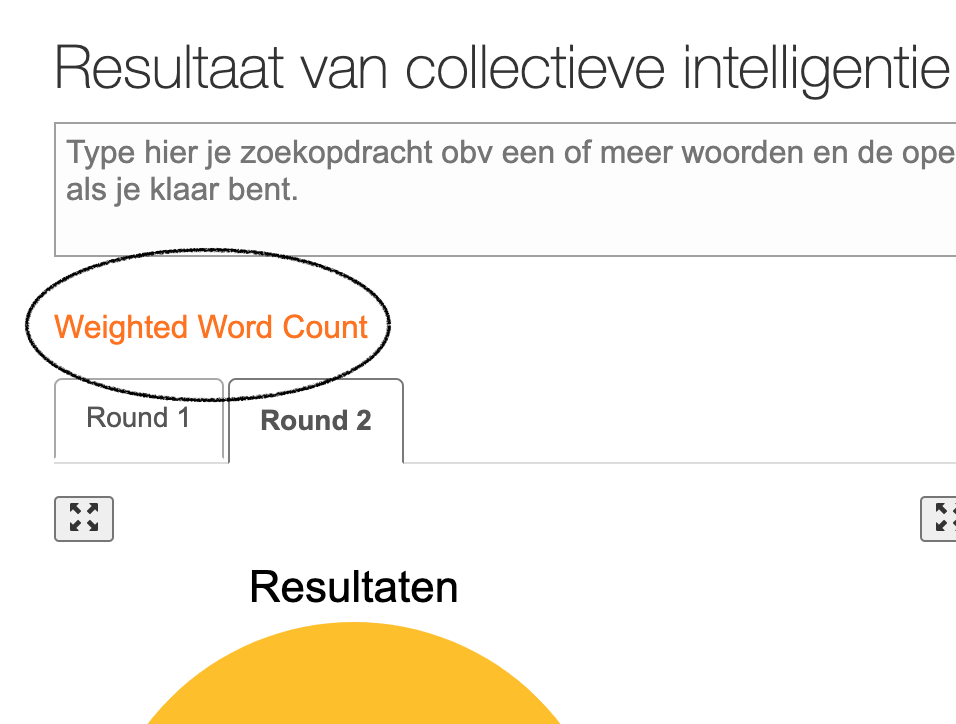 tot +3 in die 2e ronde. We wegen van elk woord, elke combinatie van 2 woorden en elke combinatie van 3 woorden, hoe belangrijk deze zijn volgens de mensen zelf, en berekenen de frequentie ervan, de weging, of dat negatief/positief was, van hoeveel mensen en of er woorden bijzitten die nog extra werden aangeklikt door deelnemers in de 2e ronde. Deze WWC kun je gebruiken om snel en relevant je zoekopdracht te verrijken voor je supervised topic modelling. Alles wat je in de WWC light box wil meenemen in je zoekopdracht en aanklikt zetten wij in je zoekopdracht-box in de achtergrond en deze wordt meteen uitgevoerd. Zo makkelijk is dat. Zo wordt topic modelling pas relevant en deze kun je samen met de tool uitvoeren.
tot +3 in die 2e ronde. We wegen van elk woord, elke combinatie van 2 woorden en elke combinatie van 3 woorden, hoe belangrijk deze zijn volgens de mensen zelf, en berekenen de frequentie ervan, de weging, of dat negatief/positief was, van hoeveel mensen en of er woorden bijzitten die nog extra werden aangeklikt door deelnemers in de 2e ronde. Deze WWC kun je gebruiken om snel en relevant je zoekopdracht te verrijken voor je supervised topic modelling. Alles wat je in de WWC light box wil meenemen in je zoekopdracht en aanklikt zetten wij in je zoekopdracht-box in de achtergrond en deze wordt meteen uitgevoerd. Zo makkelijk is dat. Zo wordt topic modelling pas relevant en deze kun je samen met de tool uitvoeren.
Kenmerken / Filtering
Als je Kenmerken hebt toegepast, kun je deze gebruiken om de resultaten voor alle vragen meteen te filteren. Je kunt er een of meer tegelijk gebruiken, waarbij het relevant is welke je eerst kiest en daarna. Je kunt je filters weer resetten. Deze Kenmerken voer je vooraf in, samen met de mailadressen van de genodigden. Het kan bijvoorbeeld gaan om afdeling, land, locatie, hoe lang al in dienst, etc. Als je deze Kenmerken vooraf niet hebt, dan vraag je deelnemers om deze informatie via profielvragen. Deze vragen kun je na afloop van de dialoog met een klik op een icoontje omzetten in Kenmerk.

ReflectionAnalysis, Grafieken en Switchers
Als je een gesloten vraag hebt toegepast, bijvoorbeeld in combinatie met een open antwoord, krijg je per vraag grafieken te zien. Als je toe hebt gestaan dat deelnemers hun gesloten antwoord mochten herzien, zie je meerdere grafieken: hun eerste standpunt en finale standpunt. Je zult zien hoe vaak deze afwijken: de 2e ronde zet mensen aan tot dieper, bewuster nadenken en daarna vullen ze je gesloten schaal nauwkeuriger in. Dat kan het verschil maken bij je besluitvorming! Bovendien wil je geen besluiten nemen op basis van informatie waar deelnemers later van zeggen “dat bedoelden wij niet zo”. Die 2e ronde is dus van kritisch belang. Je kunt klikken op ‘switchers‘ om te zien welke veranderingen van standpunten plaatsvonden en de motivering waarom. De ReflectionAnalysis is beschikbaar voor de Likert schalen en laat in detail zien hoe mensen wijzigden van standpunt gedurende en door de 2e ronde.
ronde zet mensen aan tot dieper, bewuster nadenken en daarna vullen ze je gesloten schaal nauwkeuriger in. Dat kan het verschil maken bij je besluitvorming! Bovendien wil je geen besluiten nemen op basis van informatie waar deelnemers later van zeggen “dat bedoelden wij niet zo”. Die 2e ronde is dus van kritisch belang. Je kunt klikken op ‘switchers‘ om te zien welke veranderingen van standpunten plaatsvonden en de motivering waarom. De ReflectionAnalysis is beschikbaar voor de Likert schalen en laat in detail zien hoe mensen wijzigden van standpunt gedurende en door de 2e ronde.
FastFinder
Als je gesloten schalen hebt toegepast én Kenmerken, tonen we samenvattingen van de resultaten via FastFinder. De radar-of ook wel spider-grafieken laten zien of sommige subgroepen van deelnemers afwijkende, cijfermatige resultaten tonen. Die uitschieters kun je snel bestuderen, door op de grafiek te klikken en de light box te openen. Vervolgens kun je op de specifieke waarde van dat Kenmerk filteren (zoals een afdeling) bij Filtering en de betreffende Top 5 nader analyseren. Zo weet je snel wat het meest gesteunde, kwalitatieve ‘waarom’ is achter de cijfermatige afwijkingen. Het heeft immers niet zoveel zin om te weten dát bepaalde subgroepen afwijkend scoren, als je niet gelijktijdig begrijpt waaróm ze afwijken en wát ze dan anders bedoelen/willen.

Cross-Silo Effect: hoe reageren subgroepen op elkaar?
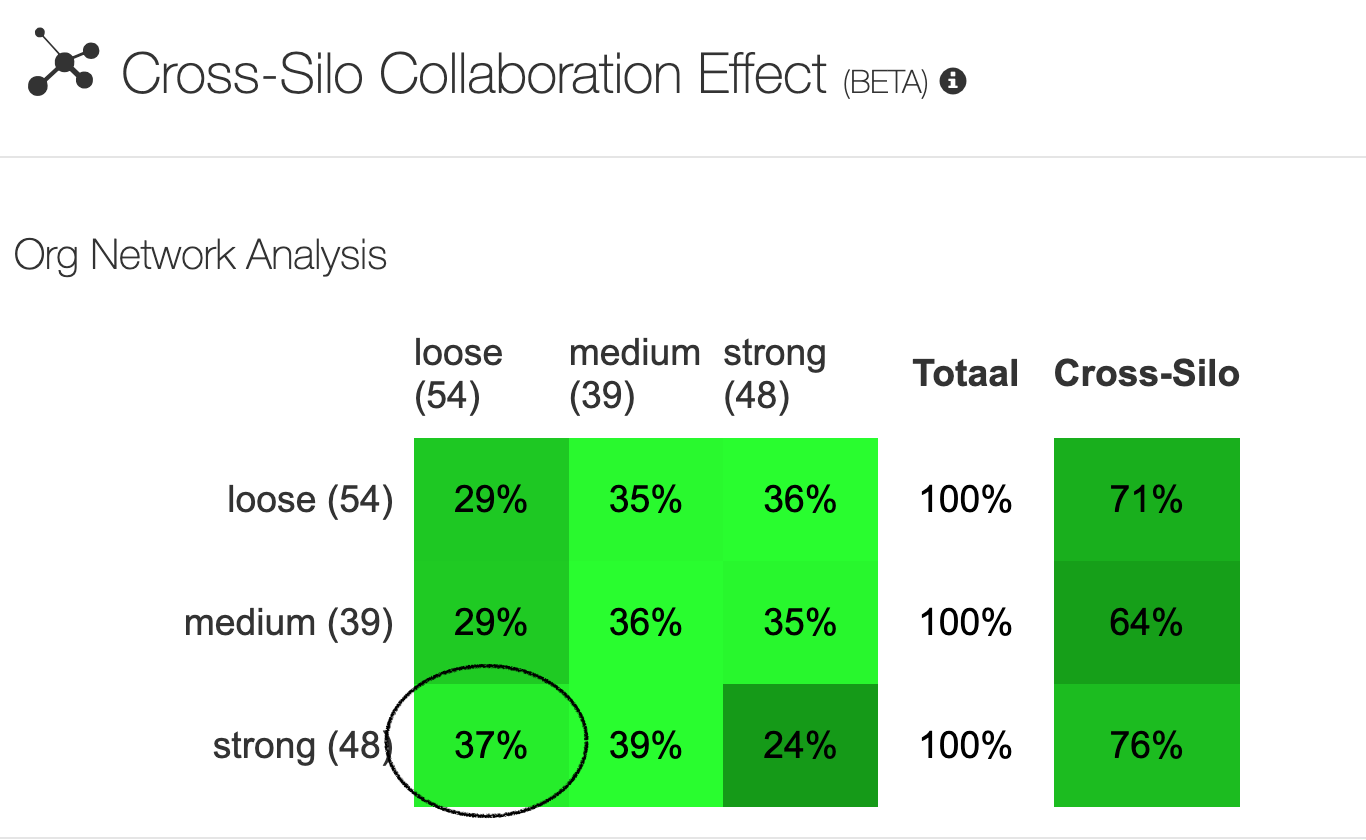
We hebben door de unieke 2e ronde een enorme hoeveelheid, relevante, context-rijke data. Hierdoor beschik jij over informatie hoe verschillende subgroepen op elkaar hebben gereageerd, van elkaar hebben geleerd, bijdragen van elkaar afwezen of juist omarmden. Jij weet dus hoe deelnemers over de grenzen van hun eigen silo heen, met andere perspectieven van deelnemers in aanraking kwamen en daarmee aan de slag zijn gegaan!
Downloads
Je kunt alle grafieken als plaatje of als excel downloaden met dus de data in excel. Dan kun je zelf bepalen wat je ermee wil doen. In je dashboard staan bovendien icoontjes aan de rechterzijde waarmee je allerlei standaard-rapportages kunt downloaden, en deze rapportages vind je ook als tabje als je in de dialoog bent, aan de rechterzijde. Als je Kenmerken hebt gebruikt zoals afdeling, regio, hoe lang al in dienst, etc, kun je deze toepassen en een maatwerk rapportage maken, bijvoorbeeld voor een specifieke manager of team. De excel rapportages kun je desgewenst bewerken en daarna als pdf opslaan en versturen. Dit zijn dus direct beschikbare rapportage mogelijkheden.
JSON files
Als je bestanden nodig hebt om in je eigen business intelligence reporting tools te gebruiken, bieden we de mogelijkheid om JSON files te downloaden. Contact ons hier als je dat wil. Hou er rekening mee dat jij of je klant daar enige technische handelingen voor moeten verrichten.
Waardering en Activiteit van de deelnemers
In het Proces tabje staan allerlei statistieken en overzichten die laten zien hoe actief de deelnemers waren in ronde 1 en ronde 2. Je ziet bijvoorbeeld dat ze enorm actief waren in ronde 2: vaak 70% of meer deelnemers die meer dan hun eigen setje van 15 bijdragen van anderen willen beoordelen; meer dan 20-40% van de deelnemers aan ronde 2 zelfs meer dan 30 bijdragen. Ook geven ze jouw dialoog een rating: dat doen ze direct na ronde 1, na ronde 2 en via de toegestuurde eindmail (mits deze aan staat om verstuurd te worden). Ze geven de dialoog een rating en vertellen daar vaak wat bij. Enorm waardevol voor je volgende dialoog en zo leer je al snel dat deelnemers opgelucht zijn dat ze serieus genomen worden, hun meningen kwijt kunnen en die kunnen zien van anderen. We krijgen meestal een 4 tot 4,6 of een schaal van 5. Enorm hoog dus. Ook zie je in dit tabje het effect van de reflectie-tijd en de 2 rondes: je ziet dat een deel van de bijdragen in de eerste helft van de looptijd van ronde 1 wordt ingediend, en een ander deel in de 2e helft. Vervolgens zie je dat dat laatste deel, dus van de langzamere deelnemers, in ronde 2 zeer hoog en vaak de meeste score ophaalt. Langzame denkers zijn vaak de betere….

Hou dit blog in de gaten, omdat we regelmatig nieuwe, half-of geheel geautomatiseerde tools en inzichten toevoegen!
Plan hier je afspraak om samen door je resultaten heen te lopen. Dat doet ons team graag!